Price research
Backstory
TL;DR: Given a list of parts-numbers (PNs), I was assigned to manually research retail prices on 4 different websites. I decided to automate this process, and earned a raise as a result. — This project was part of my employement at IVECO, a commercial vehicle manufacturing company. A niche of their product portfolio was the second-line, called NexPro. It offered to renew older vehicle’s components with products at competitive prices, while still guaranteeing reliability.
As part of the DACH’s aftersales department, the newest working student (or the one with the least work load) was, from time to time, assigned to research respective market prices, to keep the NexPro line competitive. For that, we were given an Excel-list of parts numbers (PNs), which were usually in the form of 10-ish digit codes, for which we had to find prices in predetermined retailer-websites (we had 4 popular websites). Some require an account to which you have to log in to, and others do not (LKW-Teile24).
When, one day, I got assigned a longer list of around 200 PNs, I made it my goal to automate this workflow. Upon succeeding I was assigned a raise, which was unprecedented for working students.
Methods
TL;DR: Although, the requests library doesn’t work for websites running JavaScripts, I found Selenium + Beautiful soup to be a good solution. I use pandas to read & write Excel-Files and handle (append/merge) different results. — If you are familiar with web-scraping, maybe the library requests comes into mind. However all websites, run a java script to display the query’s results, which is not done before the website is finished loading. Therefore requests accesses the HTML-Code with an empty query list. Also, the push-request to log into one of the websites didn’t work as intended. I used Python’s Selenium library for this project. Hence, in order to locally run this program, the download of a webdriver (in this case Chrome) is necessary along with the respective browser version. For the virtual machine of this project, I amended the initialization notebook so that the enviroment is automatically initiated every time the machine is booted up. For navigating through the HTML-Code I used BeautifulSoup. To read the Excel-list which is giving the input, in form of the PNs that are supposed to be looked for, I used pandas. To store the results I used Python lists which are expanded after every query, and at the end converted to pandas DateFrames in order to append and merge different DataFrames and save them back into an Output.xlsx and/or to display them right in the notebook.
How does it work?
You can try it yourself, just contact me via E-Mail and I will provide you with the necessary rights to execute the Notebook. Please note that you might have to quickly sign up on Deepnote if you have not used it before.

Once all the PNs have been queried, the file is saved in an Excel sheet for further inspection.
Hence, I am left to give you a simple visualization that is providing information about the distribution of prices for each PN, coloring each retailer differently, but also pointing out the medians of said price distributions.
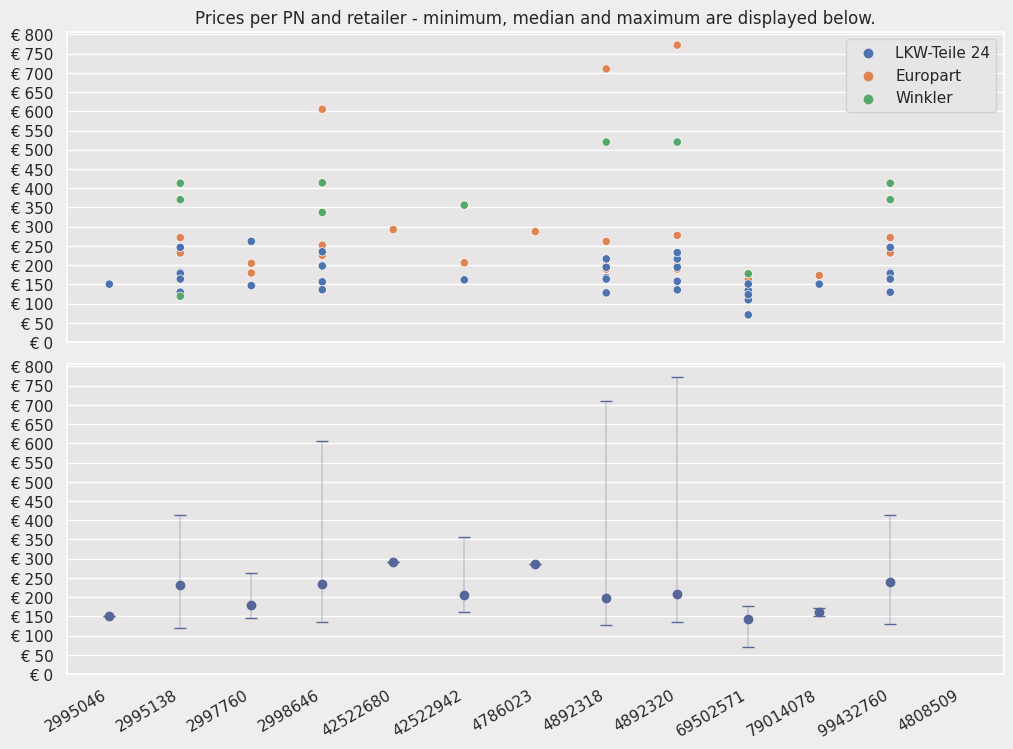
Conclusion
Business Conclusion
- LKW-Teile 24 is on average the cheapest retailer.
- The median could be a good anchor to choose a new price of own product.
- Check for highly right-skewed price distributions
- In which case a price slightly lower than the median should be considered.
- As most retail-offers can be underbid with only a small trade-off
Coding Conclusion
- Selenium offers a good alternative to the requests library if an API is not available or a push request for logins is not possible.
- Websites should not be overtaxed with high-paced scraping attempts.
- I learned…
- to work with Selenium and its drawbacks
- how to set up the necessary drivers and the environment
- about the nature of java scripts in a website, and implicit waits to handle them properly
- I improved…
- my skills to navigate through an HTML with the XPath of a given tag
- my understanding of building more complex projects over multiple python files
- my literacy about managing files, especially pandas read and write methods.
- Through iteration I strengthened…
- my python skills, with regards to functions, return statements, lists & tuples
- my memory about the methods of pandas’ DataFrame-class
- my data visualization skills with matplotlib and seaborn