An NLP analysis.
Preparation
Before starting this project I had some rough knowledge on the concept of bag-of-words for the vectorization of text-documents, as I had to reconstruct Google’s algorithm on identifying article-simlarity for one of my courses in my Information Systems program. In that course I also learned about tf-idf (term frequency, inverse document frequency), which is a model where each word is given a weight that increases with the frequency of that word in that specific text (tweet) but decreases in importance if that word is encountered in most texts. Hence, overall rare words, though frequently present in a specific text characterize that text the most.
The concept of NLP was, however, fairly new to me. So I took an introductory course in Datacamp.
Data Extraction
For everyone living under a rock, Donald J. Trump was suspended from Twitter following the election results. His last tweet dates back to the 8th of January 2021. Luckily, there is a website called The Trump Archive where I was able to download all tweets.
For Joe Biden, I found a dataset on Kaggle. However, they did not include tweets from November 2020 onwards. Hence, I accessed the Twitter-API, which luckily gave me tweets reaching further back, than the other dataset’s last entry. On my GitHub you can see the code created in order to retrieve the tweets from the Twitter-API.
Funfact!
MAKE AMERICA GREAT AGAIN!
… was posted by Trump 51 times in all-caps and without any further context.
Transformation & loading
The full transformation can be seen in the DeepNote project. As a quick summary, Joe Biden’s tweets had to be checked for duplicates, but both datasets included the Tweet-ID, so that was no problem. Tweets only including a Twitter link were removed, and Twitter links were removed in general. Both datasets were then labelled before being appended. For the upcoming NLP, I trimmed the dataset to the timespan where both were active (Biden restarted tweeting in 2018) and then took a sample of Trump’s tweets to match the amount of Biden’s. I did this so that the model was not overfitting for Trump, which would sacrifice the performance for the classification of Biden’s tweets.
Vectorization and fitting
As mentioned before, a tf-idf vectorization might be a good approach for NLP. However, tweets can follow their own rules of grammar and structure, as there is a limit to the number of characters used, thus, consisting mostly of key words. Therefore, a classic count vector might be just as good in this case.
In NLP it is also common to exclude stop words that do not give any insight on the texts topic. However, as we only have two different authors which supposedly should address the same topics in public, it might be possible that differentiating the tweets according to key words might turn out to be quite difficult. On the other hand, there could be a significant difference in the use of the English language between the two, see here. For that reason, I also used a simple count vectorization to compare it to the tf-idf vectorization.
Models
For the models I took a Naive Bayes approach to see which vectorization is the most appropriate and a Linear Support Vector Classifier to later graph the key words that are the most related to each U.S. President.
Results
Accuracy
For the Naive Bayes, I randomized the train and test samples 100 times. The resulting accuracy scores are summarized in the following table.
| descriptive statistic | tf-idf | tf-idf no stop words | count |
|---|---|---|---|
| Mean | 0.7746 | 0.6808 | 0.7746 |
| Std | 0.01 | 0.036 | 0.01 |
| Min | 0.7548 | 0.6307 | 0.7457 |
| 25% | 0.7669 | 0.6443 | 0.7669 |
| Median | 0.7749 | 0.7024 | 0.7744 |
| 75% | 0.7832 | 0.7137 | 0.7823 |
| Max | 0.8002 | 0.7302 | 0.7937 |
As for the model without stop words accuracy scores are much lower, while the other two score very similar throughout.
Confusion matrices
Looking at the confusion matrices it becomes clear that the model excluding stop words is struggling to properly classifying tweets from Joe Biden. Considering the other two, the tf-idf model is slightly better with Biden’s tweets, and the count model is better with Trump’s tweets.
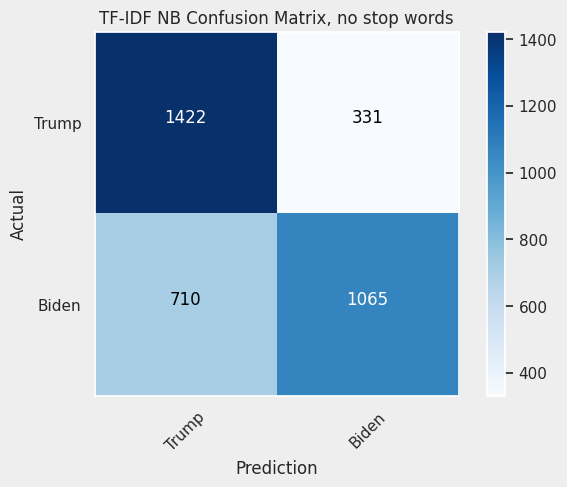
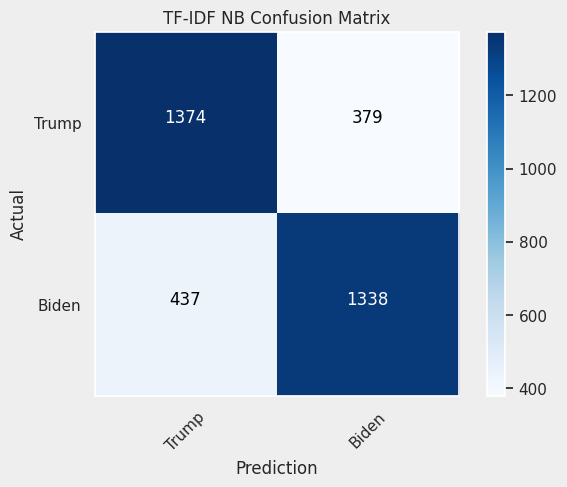
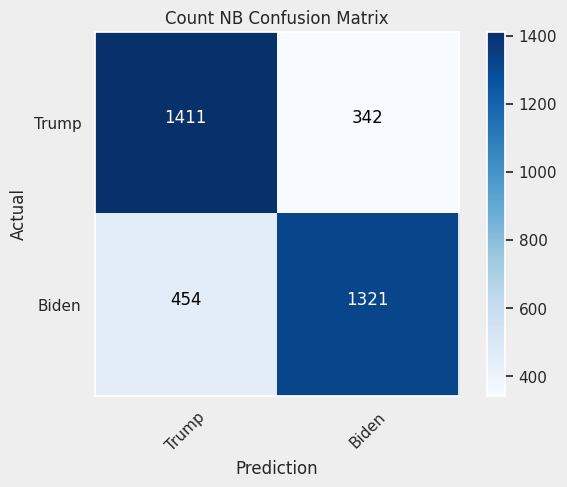
Top words
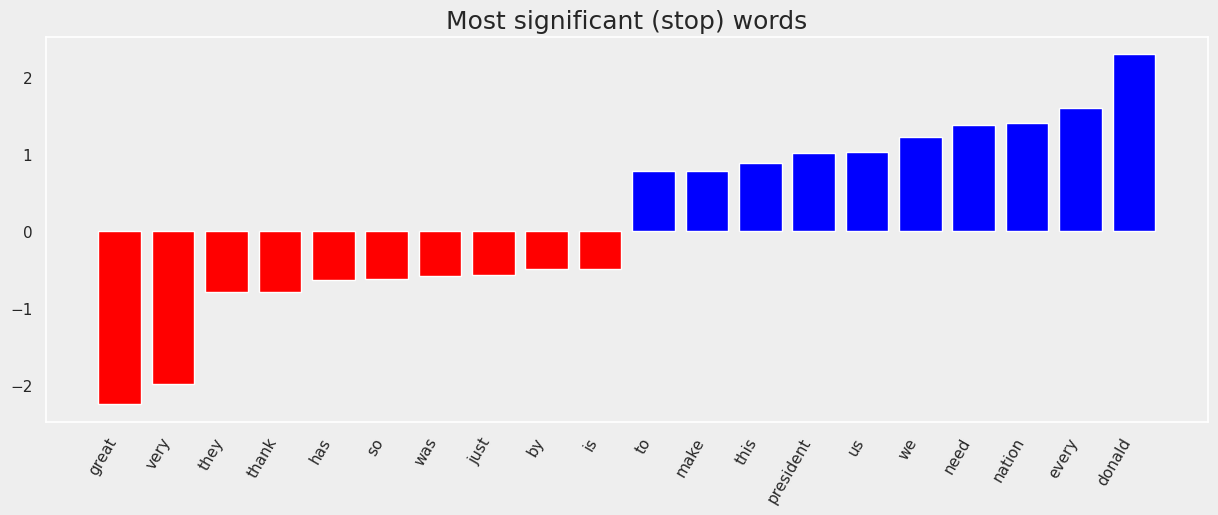
Lastly, we can take a look at the top features of the SVC model. The features with a red bar resemble key words that would make a tweet more likely to be authored by Trump, while the blue bars belong to Biden’s favorite words. Interestingly, there are not many key words that are related to Trump.
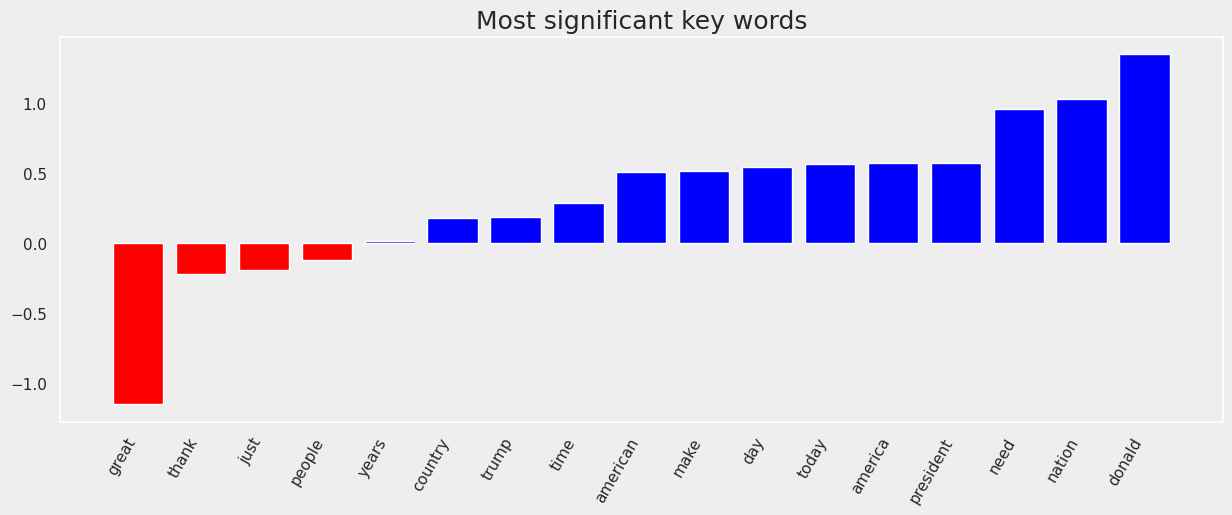
When including stop words, on the other hand, one can see clear differences in the use of pronouns. Biden is more inclusive with we and us in addition to nation, america/n and countr, and Trump rather refers to others with they. Furthermore, Trump has a more definite tone using words like very, has, was, and is. Biden is problem focused, speaking of need and make. Pointing out problems might also be a more favorable approach for the candidate running for the opposition.
Wordcloud!
I always wanted to make a WordCloud and this is the perfect (and only) opportunity for it. Here, english stop-words are excluded with the gensim library.
